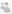width=96> Кількість кімнат
.
Включення (критерій: ймовірність F-включення> =, 050)
a Залежна змінна: Ціна
2. Змінна Х4 В«РайонВ» є фіктивною змінною, так як має 2 значення: 3-приналежність до центрального району В«РадянськийВ», 4 - до периферійного району В«ПівнічнийВ».
3. Побудуємо лінійну модель регресії для всіх факторів (включаючи фіктивну змінну Х4).
Отримана модель:
У = 348,349 + 35,788 Х1 -217,075 Х4 +305,687 Х7
Оцінка якості моделі.
Коефіцієнт детермінації R2 = 0,807
Показує частку варіації результативної ознаки під впливом досліджуваних факторів. Отже, близько 89% варіації залежної змінної враховано і обумовлено в моделі впливом включених факторів.
Коефіцієнт множинної кореляції R = 0,898
Показує тісноту зв'язку між залежною змінною У з усіма включеними в модель пояснюючими факторами.
Стандартна помилка = 126,477
Коефіцієнт Дарбіна - Уотсона = 2,136
Перевірка значущості рівняння регресії
Значення критерію F-Фішера = 41,687
Рівняння регресії слід визнати адекватним, модель вважається значущою.
Самий значимий фактор - кількість кімнат (F = 41,687)
Другий за значимістю фактор-загальна площа (F = 40,806)
Третій за значимістю фактор-район (F = 32,288)
4. Побудуємо лінійну модель регресію з усіма факторами (крім фіктивної змінної Х4)
За ступеня впливу на показник В«ЦінаВ» розподілили:
Самий значимий фактор - загальна площа (F = 40,806)
Другий за значимістю фактор-яка кількість кімнат (F = 29,313)
5. Включені/виключені змінні
Модель
Включені змінні
Виключені змінні
Метод
1
Загальна площа
.
Включення (критерій: ймовірність F-включення> =, 050)
2
Район
.
Включення (критерій: ймовірність F-включення> =, 050)
3
Кількість кімнат
.
Включення (критерій: ймовірність F-включення> =, 050)
a Залежна змінна: Ціна
6. Побудуємо лінійну модель регресії для найбільш впливових факторів з фіктивною змінною, в нашому випадку вона і є одним з впливових чинників.
Отримана модель:
У = 348,349 + 35,788 Х1 -217,075 Х4 +305,687 Х7
Оцінка якості моделі.
Коефіцієнт детермінації R2 = 0,807
Показує частку варіації результативної ознаки під впливом досліджуваних факторів. Отже, близько 89% варіації залежної змінної враховано і обумовлено в моделі впливом включених факторів.
Коефіцієнт множинної кореляції R = 0,898
Показує тісноту зв'язку між залежною змінною У з усіма включеними в модель пояснюючими факторами.
Стандартна помилка = 126,477
Коефіцієнт Дарбіна - Уотсона = 2,136
Перевірка значущості рівняння регресії
Значення критерію F-Фішера = 41,687
Рівняння регресії слід визнати адекватним, модель вважається значущою.
Самий значимий фактор - кількість кімнат (F = 41,687)
Другий за значимістю фактор-загальна площа (F = 40,806)
Третій за значимістю фактор-район (F = 32,288)
7. Фіктивна змінна Х4 є значимим чинником, тому доцільно включити її в рівняння.
Інтервальні оцінки параметрів рівняння показують результати прогнозування за моделлю регресії.
З імовірністю 95% обсяг реалізації в прогнозованому місяці складе від 540,765 до 1080,147 млн. крб.
8. Визначення вартості квартири в елітному районі
Для 1 кімн У = 348,349 + 35,788 * 74, 5 - 217,075 * 3 + 305,687 * 1
Для 2 кімн У = 348,349 + 35,788 * 74, 5 - 217,075 * 3 + 305,687 * 2
Для 3 кімн У = 348,349 + 35,788 * 74, 5 - 217,075 * 3 + 305,687 * 3
в периферійному
Для 1 кімн У = 348,349 + 35,788 * 74, 5 - 217,075 * 4 + 305,687 * 1
Для 2 кімн У = 348,349 + 35,788 * 74, 5 - 217,075 * 4 + 305,687 * 2
Для 3 кімн У = 348,349 + 35,788 * 74, 5 - 217,075 * 4 + 305,687 * 3
Глава 2. Кластерний аналіз
Завдання: Дослідження структури грошових витрат і заощаджень населення.
У таблиці представлена структура грошових витрат і заощаджень населення по регіонах Центрального федерального округу Російської федерації в 2003 р. Для наступних показників:
В· ПТіОУ - покупка товарів і оплата послуг;
В· ОПІВ - обов'язкові платежі та внески;
В· ПН - придбання нерухомості;
В· ПФА - приріст фінансових активів;
В· ДР - приріст (Зменшення) грошей на руках у населення.
Рис. 8 Вихідні дані
Потрібно:
1) визначити оптимальну кількість кластерів для розбиття регіонів на однорідні групи за всім группіровочним ознаками одночасно;
2) провести класифікацію областей ієрархічним методом з алгоритмом міжгрупових зв'язків і відобразити результати у вигляді дендрограмми;
3) проаналізувати основні пріоритети грошових витрат і заощаджень в отриманих кластерах;
4) порівняти отриману класифікацію з результатами застосування алгоритму внутрішньогрупових зв'язків.
Виконання:
1) Визначити оптимальну кількість кластерів для розбиття регіонів на однорідні групи за всім группіровочним ознаками одночасно;
Для визначення оптимальної кількості кластерів потрібно скористатися ієрархічної кластерним аналізом і звернутися до таблиці В«Кроки агломераціїВ» до стовпцю В«КоефіцієнтиВ».
Ці коефіцієнти подразумевают відстань між двома кластерами, визначену на підставі обраної дистанційної заходи (Евклідів відстань). На тому етапі, коли міра відстані між двома кластерами збільшується стрибкоподібно, процес об'єднання в нові кластери необхідно зупинити.
У підсумку, оптимальним вважається число кластерів, рівне різниці кількості спостережень (17) і номери кроку (14), після якого коефіцієнт збільшується стрибкоподібно. Таким чином, оптимальна кількість кластерів дорівнює 3. (Рис.9)
статистичний математичний аналіз кластерний
Рис. 9 Таблиця В«Кроки агломераціїВ»
2) Провести класифікацію областей ієрархічним методом з алгоритмом міжгрупових зв'язків і відобразити результати у вигляді дендрограмми;
Тепер, використовуючи оптимальну кількість кластерів, проводимо класифікацію областей ієрархічним методом. І у вихідних даних звертаємося до таблиці В«Належність до кластерівВ». (Рис.10)
Рис. 10 Таблиця В«Належність до кластерівВ»
На Рис. 10 чітко видно, що в 3 кластер потрапили 2 області (Калузька, Московська) і м. Москва, у 2 кластер дві (Брянська, Воронезька, Івановська, Липецька, Орловська, Рязанська, Смоленська, Тамбовська, Тверська), в 1 кластер - Білгородська, Володимирська, Костромська, Курська, Тульська, Ярославська.
Рис. 11 Дендрограмма
3) проаналізувати основні пріоритети грошових витрат і заощаджень, в отриманих кластерах;
Для аналізу отриманих кластерів нам потрібно провести В«Порівняння середніхВ». У вихідному вікні виводиться наступна таблиця (Мал. 12)
Рис. 12 Середні значення змінних
У таблиці В«Середніх значень В»ми можемо простежити, яким структурам віддається найбільший пріоритет в розподілі грошових витрат і заощаджень населення.
В першу чергу варто відзначити, що найвищий пріоритет у всіх областях віддається покупці товарів і оплату послуг. Більше значення параметр приймає в 3 кластері.
2 місце з...